
Algorithmic Legitimation Paradox
What is that?

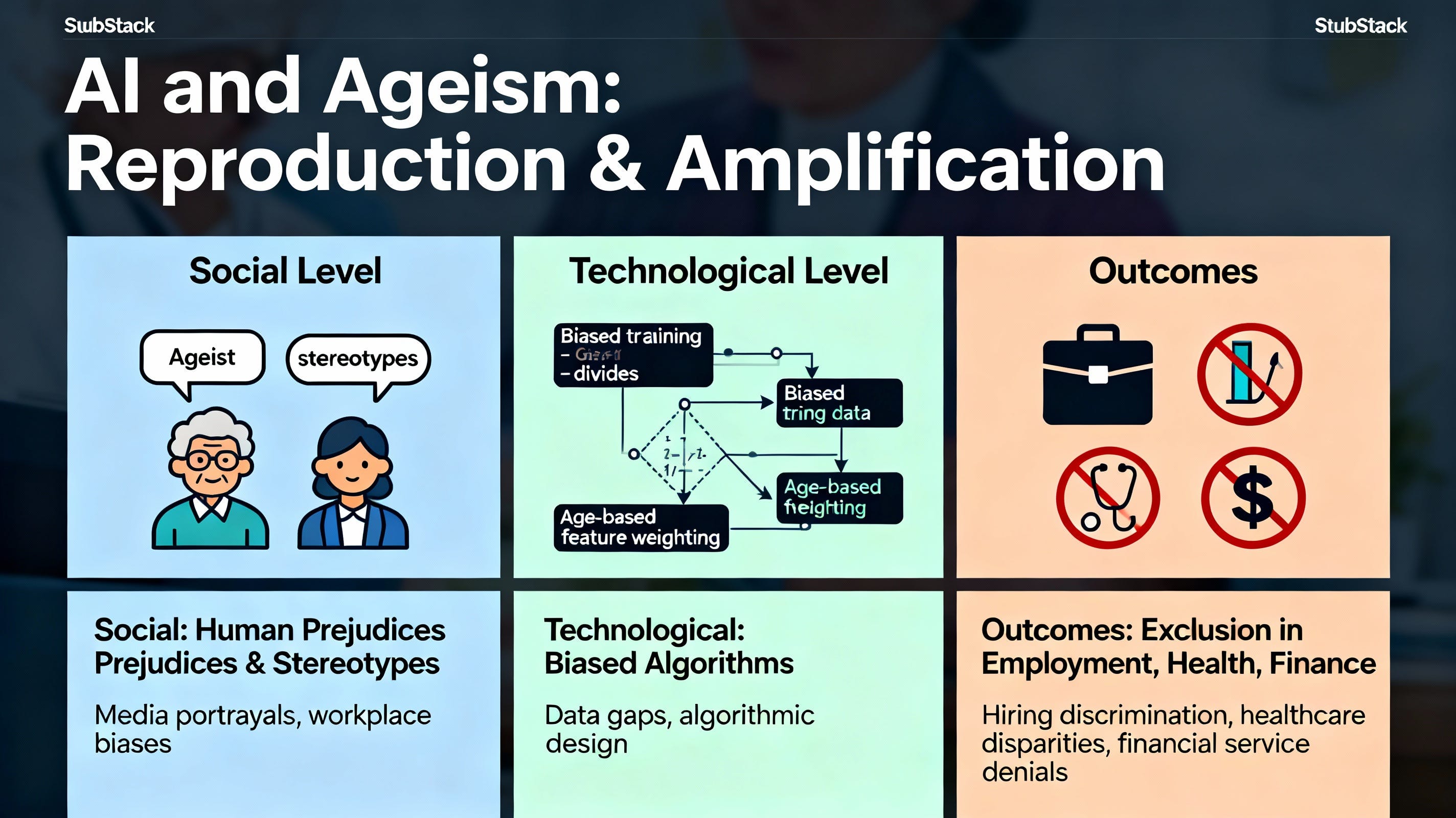
It’s an elegant way to refer to the process by which a deeply rooted social prejudice (such as ageism) is absorbed by Artificial Intelligence (AI) systems and, when reproduced by them, acquires a (false) aura of objectivity and mathematical truth, making it more difficult to combat.
Let’s analyze this briefly:
1. The Root of All Evil: Social Prejudice
AI and machine learning systems are often perceived as tools capable of making objective, fast, and neutral decisions, benefiting from not making human errors.
However, algorithmic bias is not caused by the algorithm itself, but by the sociotechnical process of its creation, which includes the business area, the data science team, and the encoding of information.
Social prejudice, such as ageism, is widespread in society and has often been called the “last acceptable prejudice” in modern culture, as it is not only an extended form of discrimination but is also normalized in some way. This social normalization has a pernicious influence on the development of AI.
Algorithmic ageism is, at its core, a human problem. It is defined as the prejudice, stereotype, or discrimination directed toward a person or group of people due to their age.
The root of ageism against older people lies in a negative and unfounded view of old age as synonymous with decline and uselessness. However, actual aging is not merely biological; it is an extensive process that encompasses diverse individual, social, and generational experiences. Therefore, old age is characteristically varied and diverse, challenging any simplistic stereotype. Furthermore, ageism is now applied to people over 45. As an extreme example, the American athlete Natalie Grabow, aged 80, holds the record for the oldest woman to complete the Ironman World Championship, achieving this feat in Hawaii in 2025. She competed in the 80-84 age category. Clearly, people cannot be pigeonholed based on their age.
According to the World Health Organization (WHO), this phenomenon manifests on three interconnected levels:
Structural: At the level of laws, policies, and social norms that, explicitly or implicitly, create disadvantages for certain age groups. For example, a company’s policy that, when seeking job candidates, states: “dynamic young person wanted...”
Interpersonal: In daily relationships, where treatment is based on stereotypes about old age, such as infantilization or the presumption of incompetence. This can occur even within one’s own family when discrimination is framed by paternalism and welfare assistance, where the older person is overprotected, their participation in daily life activities is diminished, or their power of decision is taken away.
Self-Inflicted: When an older person internalizes the negative social image, affecting their self-image, behavior, and limiting their own potential. An example is when an older person internalizes the belief that they are “too old” for technology and avoids it, or limits their own development by avoiding adaptation to new technologies.
The data confirms the prevalence of a negative image of old age. A study conducted in Chile revealed that 45% of people believe that those over 70 have a low social standing, and 28% consider them incompetent3. These perceptions contrast dramatically with the reality: 86% of older people are not dependent. This massive gap between an unfounded social perception and empirical reality is precisely the toxic fuel that feeds AI models. By being trained on data that reflects these generalized beliefs, algorithms learn to associate advanced age with incompetence and dependency, transforming a cultural prejudice into an automated decision criterion.
2. Legitimation through Mathematical Objectivity
This is where the core of the paradox lies: AI a technology that promises fast, superior, and presumably more neutral results, becomes a mechanism that transforms entrenched human prejudices into automated decision criteria.
Social prejudices translate into systematic technical errors throughout the AI life cycle. Algorithmic bias is not caused by the algorithm itself, but by the sociotechnical process of its creation, which involves the collection and encoding of training data by the data science team, as well as instructions from the business area. Following the conceptual framework of AI Ageism proposed by Justyna Stypinska, the manifestation of the problem is analyzed at the technical level, from data collection to the final algorithm design6. These mechanisms not only replicate ageism but also amplify it, giving it a new scale and an appearance of scientific objectivity.
Encoding of Prejudice: The algorithmic system, which is a technological tool perceived as inherently objective, takes implicit social prejudice and encodes it as an “immutable mathematical truth.” This encoding occurs when the algorithm “learns” from the correlation of data rather than causality, lacking the capacity to understand the difference. Furthermore, developers can integrate the algorithm with subjective rules based on their own conscious or unconscious biases.
Veil of Efficiency: The resulting discrimination is legitimized under the veil of algorithmic efficiency. This gives social prejudice a new layer of legitimacy, opacity, and scalability. A critical mechanism in this phase is the feedback loop, where AI systems use biased results as input data for future decisions. In this way, the algorithm continuously learns and perpetuates the same biased patterns, leading to increasingly biased outcomes.
Difficulty of Correction: Once the bias has been embedded and justified as an optimized or “logical” result based on data patterns, the discrimination becomes more difficult to trace and correct. The difficulty persists, even if the algorithm were technically neutral, due to evaluation bias, which occurs when the algorithm’s results are interpreted based on the preconceived notions of the people involved, rather than objective results. Organizations using biased AI systems face significant legal and reputational risks.
In this way, the algorithm not only replicates ageism but validates it structurally. This expanded concept of AI ageism 7seeks to move beyond the limited use of the term “bias” as the dominant epistemological tool, recognizing the complex sociotechnical interdependencies of the AI creation process8.
Imagine that AI is a photocopier of society. If you feed it a document containing human errors and prejudices (the historical and biased data), the machine, being a technical and supposedly neutral device, not only reproduces the document faithfully but does so on a massive scale and with permanent ink. The result (algorithmic discrimination) is then presented as an “objective” and irrefutable copy of reality, making the original error nearly impossible to erase.
In a future post, we will look at the mechanisms that fuel this paradox and the strategies that can be implemented to mitigate biases.
Bibliography:
Edadismo: Imagen social de la vejez y discriminación por edad (Chile): https://observatorioenvejecimiento.uc.cl/wp-content/uploads/2021/07/Reporte-Observatorio-Edadismo.pdf
AI ageism: a critical roadmap for studying age discrimination and exclusion in digitalized societies:
https://pmc.ncbi.nlm.nih.gov/articles/PMC9527733/
One of the mechanisms I've found is "consensus". So when you go to look it's the majority of material available for training to the web.
Look at how Grok can skew with X input.
This points to the LLM itself, either you train it after the box in your instantiation or you handwave helplessly at the extractor matrix and its economic model.
As for studies, do you have a good prompt/filter/focused collaborator who will separate the wheat from the chaff so that you can 'clearly' see what is what?
Or are you reading with bare eyes and an out of the box 'confirminator'?